MAGYAR ROVÁS
maGar rovás
Ha nincsen gyökér, nincsen fa
ha ninCen Gökér, ninCen fa

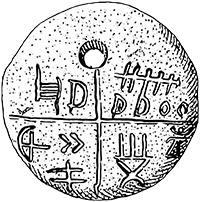
Eszék közelében fellelt bronztükör felirata
2003. augusztusában a horvátországi Szerémség területén fémkeresővel egy bronztükröt találtak. Megtalálója nem kívánta felfedni kilétét, így közvetítőkön keresztül juttatta el a leletet az illetékesekhez. A tükröt a Vinkovci Városi Múzeumban őrzik A10167 azonosító...

Erdélyi Rovó Oskola
A Romániai Magyar Cserkészszövetség létrehozta az Erdélyi Rovó Oskolát.
A leckéket filmre vették, melyből 90 részes oktatófilm kerekedett.

JÓKOGGY!
Egy ezerhatszáz éves, a Jenyiszej folyó forrás-vidékéről származó, Kizlaszov orosz régész által feltárt szikla- és barlangrajzokkal együtt összegyűjtött szövegeket a megtaláló régész megfejteni nem tudta.

Ilyen kiszolgáltatottan, mi múlik rajtunk a földi létben?
(Az írás végén hangzósított változatban is.) „Az a hit, amelyet nem támaszt alá értelem, az babona!” Hang – 2430. Hitben élő ember vagyok. Az itt csokorba szedett tények méginkább megtámasztották hitemet. Neumann János matematikusról, a számítógép atyjáról tudjuk,...

Rovásoktatás filmen
A még 2012-ben készített 5 részes rovás oktató film – Rovás oktatása róni tanulóknak címmel – 2013-2022-ig volt elérhető. Most, javított hanggal ismét föltöltésre került mind az 5 rész.

Jézus-arc tükrözött képei
Ismeretes, hogy az emberi arc két fele senkinél sem azonos minden részletében, ha azt a függőleges tengelyén tükrözzük. De ha a tükör elé állunk, s szemügyre vesszük arcunk két felét, láthatjuk, nincs számottevő különbség. Ha azt a függőleges tengely mentén...

Mit jelent a fandangó, honnan származik?
Ezeket a sorokat úgy írom, hogy az érintett területek egyikében sincs semmilyen alapképzettségem, mérnök vagyok. Itt inkább az útkeresést, a logikai összefüggéseket írom le, korlátozott ismeretanyagom felhasználásával és lelki motivációval. Jó 20-30 éve, mikor...

Legújabb szabványszáma rovás jelkészletünknek
Változatlan tartalommal, de új szabványszám alatt szerepel mostantól az Old Hungarian rovás jelkészlet.

HANG-idézetek kártyákon
A kártyahúzás lehetőségével játékos formában juthat hozzájuk, hogy azok kézzelfogható segítséget jelenthessenek az Ön mindennapjaiban. Az itt https://magyarrovas.hu/a-hang/ részletezett tartalom kapható készen a dobozba helyezett kártyákkal. 14,5 x 14,5 x 8 cm-es...

Újabb rovásírásos korong Tatárlakán és egy ráadás…
Írta és az angol szöveget fordította: Friedrich Klára
Adószámunk: 19551827-1-03
Magyar rovás-jelkészlet

Ki ír itt?


